MySQL批量插入大量(10万条)数据的性能对比
- 11136
- MySQL
- 42
- super_dodo
- 2017/01/19
MySQL的各个版本之间的改进和优化以及变化都很大,我们的服务器性能以及复杂度也变化很大。小编dodo只是做了一个简单的本地测试。以下数据仅供参考,实践实践验证里的唯一标准。
本地服务器:Windows CPU--i7 内存8G 64位的系统 MySQL版本:5.7.11 PHP框架: Yii2 场景需求如下: 目标:插入10万条文章的列表数据(没有文章内容) 数据库中id是自增主键 插入字段:栏目ID,文章名称,文章类型,文章状态,作者ID,创建时间 A :一次1条的插入 ???时间 B :一次100条 ???时间 C :一次1000条 ???时间 D :一次10000条 ???时间 备注说明:插入慢只是一个问题,不小心mysql就卡主了。 以下结果在特定环境下有效。仅供参考.
直接上代码如下:
namespace app\controllers;
use Yii;
use yii\web\Controller;
class PostController extends Controller{
public function actionBatch(){
set_time_limit(0); //不限时
ini_set('memory_limit','512M'); //内存
$each_num = Yii::$app->request->get('each_num',1); //每次执行的数目
$do_num = Yii::$app->request->get('do_num',1); //执行多少次
$tableName = 'post_list'; //要插入的表的名称
$field = ['name','cate','type','status','user_id','create_time'];//要插入的字段
$time_start = self::microtime_float(); //开始时间
for($i = 1; $i < $do_num; $i++){
$insertData = self::generateInsertData($each_num); //生成数据
Yii::$app->db->createCommand()->batchInsert($tableName,$field,$insertData)->execute();
}
$time_end = self::microtime_float();
$time_gap = $time_end - $time_start;
$data['time_start'] = $time_start;
$data['time_end'] = $time_end;
$data['time_gap'] = $time_gap;
return $this->render('index',['data'=>$data]);
}
//生成x条记录
public static function generateInsertData($num){
// $field = ['name','cate','type','status','user_id','create_time'];//要插入的字段
// 栏目ID,文章名称,文章类型,文章状态,作者ID,创建时间
for ($i=0; $i < $num; $i++) {
$insertRow = [];
$insertRow[] = '这是一篇优秀的文章'.mt_rand(0,10000); //文章名称
$insertRow[] = mt_rand(0,1000); //栏目ID---cate
$insertRow[] = mt_rand(1,3); //文章类型--type
$insertRow[] = mt_rand(1,2); //文章状态--status
$insertRow[] = mt_rand(1,100); //作者ID---user_id
$insertRow[] = date('Y-m-d H:i:s'); //发布时间
$insertData[] = $insertRow;
}
return $insertData;
}
//微秒
public static function microtime_float(){
list($usec, $sec) = explode(" ", microtime());
return ((float)$usec + (float)$sec);
}
}
-- ----------------------------
-- Table structure for `post_list`
-- ----------------------------
DROP TABLE IF EXISTS `post_list`;
CREATE TABLE `post_list` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`cate` int(10) unsigned NOT NULL DEFAULT '0',
`type` tinyint(3) unsigned NOT NULL DEFAULT '0',
`status` tinyint(3) unsigned NOT NULL DEFAULT '0',
`user_id` int(10) unsigned NOT NULL DEFAULT '0',
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4;
[/php]
执行结果如下:请各自领会.

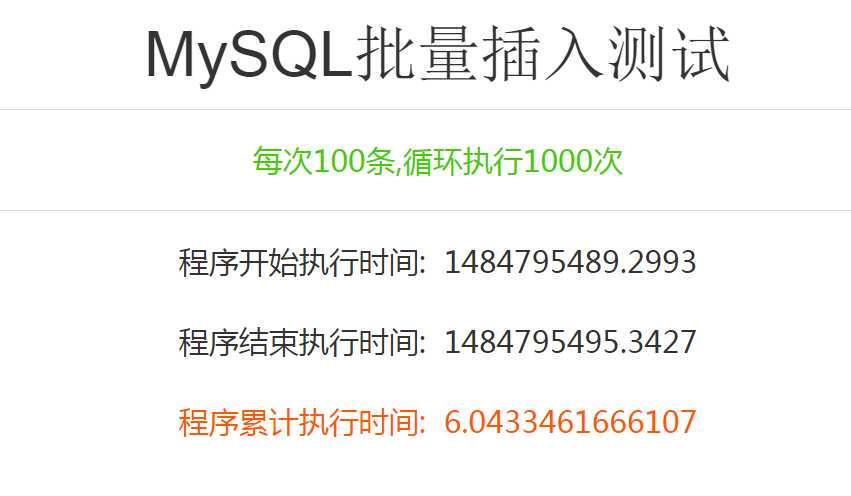
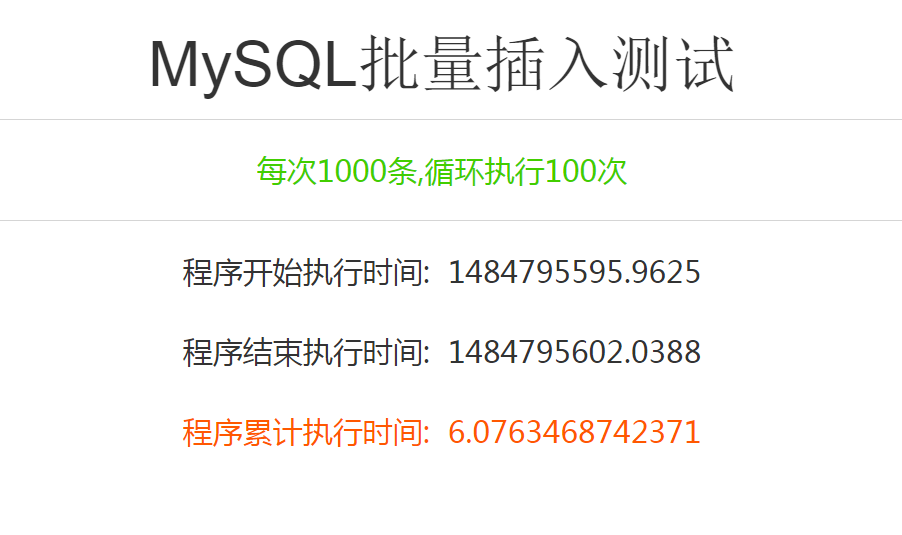
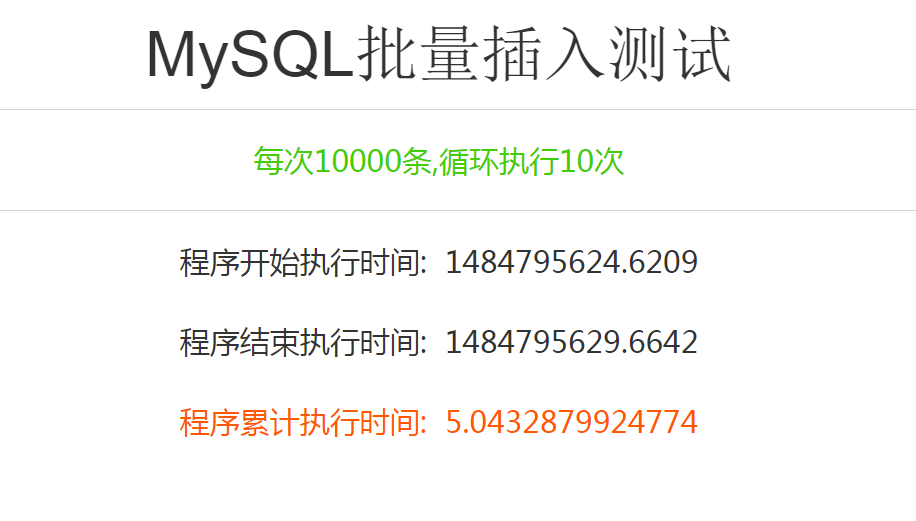
温馨提示,以上数据仅供参考,服务器的效率和你面对的业务逻辑不仅仅如此。你还需要明确以下几点:
大多数情况下一次又多少批量,并不是单词越多越好,考虑内存以及IO等。
一次一条的情况下,不仅仅是执行效率低下,更多的是会造成并发,甚至把你的服务器down了。
正式环境,面对用户的时候你应该考虑更多。
每次存的字段多少,服务器性能都应该考虑。
补充说明:由于数据库插入时,需要维护索引数据,无序的记录会增大维护索引的成本。我们可以参照innodb使用的B+tree索引,如果每次插入记录都在索 引的最后面,索引的定位效率很高,并且对索引调整较小;如果插入的记录在索引中间,需要B+tree进行分裂合并等处理,会消耗比较多计算资源,并且插入 记录的索引定位效率会下降,数据量较大时会有频繁的磁盘操作。
1. SQL语句是有长度限制,在进行数据合并在同一SQL中务必不能超过SQL长度限制,通过max_allowed_packet配置可以修改,默认是1M,测试时修改为8M。
2. 事务需要控制大小,事务太大可能会影响执行的效率。MySQL有innodb_log_buffer_size配置项,超过这个值会把innodb的数据刷到磁盘中,这时,效率会有所下降。所以比较好的做法是,在数据达到这个这个值前进行事务提交。
实践是检验真理的唯一标准-----胡福明,男,1935年7月生, 江苏无锡人。1955年9月就读于北京大学新闻专业。


相关阅读
- 通过Google API客户端访问Google Play帐户报告PHP库
- PHP执行文件的压缩和解压缩方法
- 消息中间件MQ与RabbitMQ面试题
- 如何搭建一个拖垮公司的技术架构?
- Yii2中ElasticSearch的使用示例
热门文章
- 通过Google API客户端访问Google Play帐户报告PHP库
- PHP执行文件的压缩和解压缩方法
- 消息中间件MQ与RabbitMQ面试题
- 如何搭建一个拖垮公司的技术架构?
- Yii2中ElasticSearch的使用示例
最新文章
- 通过Google API客户端访问Google Play帐户报告PHP库
- PHP执行文件的压缩和解压缩方法
- 消息中间件MQ与RabbitMQ面试题
- 如何搭建一个拖垮公司的技术架构?
- Yii2中ElasticSearch的使用示例